Dynamic/Automatic Ontology/KB Formation and Update, or
Dynamic/Automatic Knowledge Integration Process:
CLASSIFICATION-BASED INTEGRATION
&
GENERALIZATION-BASED INTEGRATION
by
Adil KABBAJ
Dynamic Knowledge Integration Process: Basic process
Different kinds of Ontology/KB/Memory and of Dynamic Integration Process
Definition Integration Process (Classification and Generazation)
Situations Integration Process (Classification and Generazation)
Rules Integration Process (Classification and Generazation)
Situations and Rules Integration Process (Classification and Generazation)
Heterogenous Integration Process
Knowledge Integration Process and other components of Amine (like Prolog+CG)
Contextual Description Integration Process
Old version of Dynamic Ontology
The information to integrate in Amine Ontology concerns a lexicon of a language (like synonymy) or it may concern the ontology itself (integration of a subtype, of a supertype, of a type definition, of an individual description, of a situation, or of a rule). The integration can be manual, using the ontology GUI or the APIs of the Kernel package, or it can be automatic (dynamic), using dynamic knowledge integration process.
Dynamic knowledge integration process concerns especially the integration of types definition description, situations description and rules description, the other cases (like the integration of individuals description or the addition of a synonym) are reduced to simple additions in the ontology and they will not be considered in this document.
Dynamic knowledge integration process concerns both Ontology and KnowledgeBase.
The underlying principles behind dynamic knowledge integration process have been presented in Kabbaj95 and more precisely in Kabbaj96 with an algorithmic formulation of the integration process. Since then, the algorithm has been refined and extended by Adil Kabbaj.
The first implementation was done in C++ (by Khalid Rouane, Adil Kabbaj, Hamid Er-Remli and Khadda Mousaid) between 1995-1998 and the second implementation was done in Java between 2000-2005 (by Karim Bouzouba and Adil Kabbaj). This second implementation was concerned by "Heterogenous Integration Process". Extension of the integration process to take into account the other cases (Types Definition Integration Process, Situations Integration Process, Rules Integration Process, Situations and Rules Integration Process, Indepth Contextual Description Integration Process) and the implementation of theses cases have been done by Adil between 2006-2007.
The distinction between the different cases of integration process, is involved by two points: a) difference in application domains, b) efficiency. The case of Heterogenous Integration Process is suited for applications where knowledge to integrate can be types definition OR situations OR rules. We have to develop and update in this case an Heterogenous ontology/KB. But for applications that are concerned by types definition only, like terminological ontology/KB, it is more efficient to use a restricted version of the "general purpose integration process". This is the case of Types Definition Integration Process. The same principle hold for the other cases: Situations Integration Process, Rules Integration Process and Situations and Rules Integration Process.
Dynamic Knowledge Integration Process: Basic process
Knowledge integration process is the process to integrate new knowledge (type definition, situation, rule, individual, synonym, etc.) in the ontology (or the KB). This process can be manual, performed directly by the user (using Ontology GUI or Ontology APIs), or it can be automatic, performed by a specific process of the system (in our case, the system is Amine Platform). "Dynamic Integration Process" is such a specific process that deals with automatic knowledge integration.
There are (at least) two kinds of Automatic Integration Process: Generalization-Based Integration and Classification-Based Integration. These two kinds of Dynamic Integration Process are provided by Amine.
Generalization-Based dynamic integration process is based on similarity and generalization-based memory (GBM) model, inspired from the work of R. Schank on dynamic memory [Schank 1 and 2] and on subsequent works on GBM [Lebowitz and Kolodner]. The main goal of GBM is to situate the new description in the memory (of the system or of the agent) and to establish connections between the new description and the other descriptions in the memory, by identification of similarities and by creation of common generalizations of the compared descriptions. Different models of GBM and of classification have been proposed and developed in the past, depending on several parameters (types of information to integrate, types of knowledge representation to use, types of memory organization, types of comparison operation, types of similarity measures, etc.).
To understand our dynamic integration process, according to its two modes, let us consider the expression of these parameters for our model:
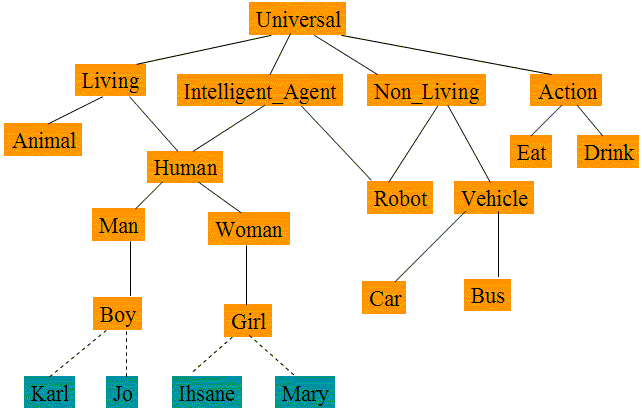
Types of information to integrate: Amine allows the development of specific ontology/KB as well as integrated ontology/KB which is composed of terminological knowledge (type hierarchy, type definition, type instantiation), assertional knowledge (specific facts about types and/or instances) situational knowledge (specific and/or generic situations concerning different types and/or instances), and rule-based knowledge. Thus, an integrated ontology/KB is a merge of several kinds of knowledge. It is closer to the "Knowledge Soup" as described by John Sowa (see Knowledge Soup Presentation and also chapter 6 of Sowa's second book [Sowa, 00]) than to a standard definition of an ontology. From the organizational perspective, integrated ontology/KB is a merge of three graphs: a graph of type hierarchy (with type definitions and instances attached to their types), a graph of situations (assertional knowledge is a special case of situational knowledge) and a graph of rules. Figure 1 (a and b) illustrates the first two graphs. The two graphs represent two generalization hierarchies; the first graph (in Figure 1.a) focuses on types (or categories or terms) while the second (Figure 1.b) focuses on situations. But it is clear that the two generalization hierarchies are complementary: type hierarchy constitutes the implicit background and the ontological support for the situation hierarchy, and in real word applications, situation hierarchy constitute a "necessary semantic complement" of the type hierarchy. How the merge of the two graphs (or generalization hierarchies) is accomplished in Amine ? The (nature of the) merge of the two graphs is strongly related to the important topic of knowledge indexation (in ontology/agent_memory): descriptions (of type definitions, of individual and of situations) are indexed, first, under types and instances that appear in the description (Figure 1.c). And due to the generalization hierarchy of descriptions (formed and updated dynamically due to the incremental integration of knowledge), descriptions are indexed also under other descriptions (Figure 1.c). In the next section, we introduce context as another type of indexical element (beside type and individual). As illustrated in this document, knowledge integration process is strongly related to (and depend on) knowledge indexation process and the question of "how to integrate knowledge ?" is strongly related to the question of "how to index knowledge ?". This document provides our answer to these questions.
(a) Graph of Type Hierarchy (with instances attached to their types)

(b) A Hierarchy of Situations (From J. Sowa)

(c) Integrated Hierarchy (of Types, Instances and Situations. Situations are paraphrased in English but they are represented in reality with CGs, see Figure 5 and the related section for more detail)
Figure 1: A Graph of Type Hierarchy, a Graph of Situations and an Integrated Graph
Type of knowledge representation used: We use CG as defined and used in Amine (see CG for more detail). Simple CGs are used to represent non-contextual descriptions and compound CGs are used to represent contextual descriptions. Some advantages of CG (over other notations) and its expressive power are highlighted by their use in Amine (to represent descriptions) and especially by their manipulation by the dynamic knowledge integration process.
Type of ontology/memory organization: recall that to each concept type and individual, we associate all (or most of) the knowledge acquired by the system concerning this type (and this individual). Such knowledge, in addition to type hierarchy and instanciation, is organized in terms of Conceptual Structures (CSs): definition of a type, canon for a type, description of an individual, description of situations (wich can be associated to both types and individuals) and description of rules. Thus, ontology in Amine is a graph of nodes that represent Conceptual Structures (CSs). Currently, six types of nodes are defined and used for the construction of ontology: Type node (which contains type definition, if provided, and canon for the type, if provided), individual node (which contains individual description, if provided), relation type node (which contains relation type definition, if provided), situation node (which contains situation description), context node (which contains the description of the context and the subject of the context), rule node (which contains rule description) and metaphor node (which contains the description of the metaphor and other related information). See Ontology for more detail. It is important to note that the generalization hierarchy concerns all these types of (ontology) nodes: a type node can be specialized by other type nodes, a situation node by other situation nodes, a context node by other context nodes, a rule by other rule nodes, and a metaphor by other metaphor nodes. Moreover, the notion of specialization is refined to take into account the use of a Type (or of an Individual) in a description (of any CS). See Ontology for more detail on the relations between ontology nodes.
Indexation scheme: The indexation scheme in Amine is expressed in terms of "pertinent types", as described below.
Type of comparison operation: as discussed below, dynamic knowledge integration process is based on the comparison between descriptions (represented by CGs). The CG comparison operation is described below.
To summarize: dynamic knowledge integration process depends on the nature and the representation of the knowledge to integrate. It depends also on the nature and the organization of the ontology/KB to create and to update.
Integrated (Heterogenous) Ontology/KB is a merge of three generalization graphs: type generalization, situation generalization and rule generalization graphs. Dynamic integration process has to construct and to update the merge of these three generalization graphs: descriptions (of type definitions, of situations and of rules) are indexed under types and individuals, and they are indexed also under other descriptions (situations and rules), depending on the result of the comparison of the involved descriptions.
Indexation scheme: pertinent types
The integration process receives not only the new description S to integrate (description of a type definition or of a situation or of a rule), but also a list of pertinent types; types that are used in S and that are considered (by the user or by a process/system) as pertinent (relevant; types that are in focus). Indeed, the dynamic integration process needs to know the pertinent types from which the new description should be integrated.
The list of pertinent types provides a list of (initial) indexes for the integration of the new description in the ontology/KB/memory. The role of pertinent types in the integration process is discussed below.
Dynamic Integration Process: Basic process
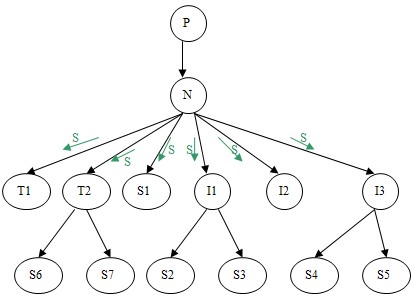
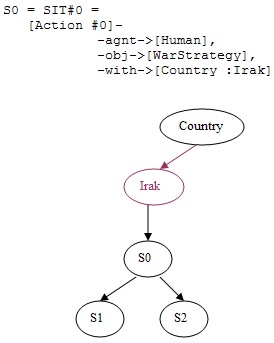
From pertinent types, the integration process locates the corresponding nodes in the ontology/KB and propagates the new description S to integrate via all these nodes (Figure 2), i.e. the integration process compares S to children of each located nodes (nd1, nd2, etc. in Figure 2).
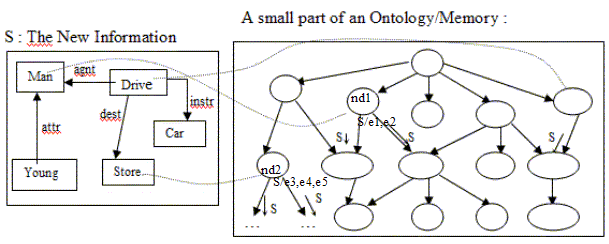
Figure 2: dynamic integration of a description S
The next steps in the integration process depend on the kind of the integration process (Generalization-Based Integration or Classification-Based Integration) and on the result of the comparison operation (between the new description and the current/existent description). We introduce the comparison operation first, and then we discuss how it is used occording to the two kinds/modes of integration process.
The Comparison Operation
Let N refers to the description of one child from the children of one located node. The comparison of S with N leads to one of the following five possibilities (Figure 3):
if S is more specific than N, then S will be compared to the descriptions that are more specific than N (i.e. descriptions that are directly indexed under N; descriptions of the nodes that are children of node(N)). If S is incomparable to all the descriptions that are under N, then node(S) will be placed as a new child for node(N),
if S is more general than N, then node(S) is placed between the father of node(N) and node(N),
if S is equal to N, then node(S) is joined with node(N),
if S has a common information with N (other than the information in the common father), and if the integration mode is Generalization-Based Integration, then a new node is created with the common information as its description and it is placed as new child of the common father and as father of node(S) and node(N). Note that no evaluation is made to determine if the common information (that results from the generalization of S and N) should be considered or not. Variants of the dynamic integration process can be developed that adopt various evaluation functions.
if S and N have nothing in common (except the common father), then nothing is done due to this comparison.

Figure 3: Results of the comparison of a description S with the current node N
Note that the new description S can reach several times the same node in the ontology/KB/memory, i.e. S can reach the same node via different paths due to the multiple sources of integration. Indeed, S is integrated via pertinent types and in the case where S is more specific than a node N, it is integrated via all the children of N. Should the new description S be compared to N, each time S reaches N ? To respond to this question, some detail on the CG comparison operation is required and this detail is related to an important point: pertinent types enable the integration process to determine entry points for the comparison operation (i.e. comparison of two descriptions, represented by CGs).
Pertinent Types suggest entry points for CG comparison
The current implementation of the dynamic integration process deals with descriptions expressed as CGs (future works will attempt to make the implementation more generic, dealing with any formalism that implements the comparison operation) and a comparison of two general CGs can produce different results (different CGs). How to proceed with these different results for one comparison ? note that the integration process will involve several calls to the comparison operation. This may leads quickly to a combinatory explosion (if we adopt general CGs) !
Matching-based CG operations in Amine (including comparison operation) are defined on functional CGs. With functional CGs, the number of different results (due to a comparison operation) is reduced. Applying a matching-based operation (generalization, maximalJoin, comparison, etc.) on two functional CGs with the specification of two entry points (two concepts from the two CGs) will lead to one result. This is the ideal situation (combinatory explosion is avoided) ! But how to determine the entry points for the comparison of two descriptions (in the context of dynamic integration process) ?
Entry point for the new description S is determined as follows: for each type T in the pertinent types list, the integration process identifies all the concepts in S with types equal to T. Each one of these concepts is considered as a possible entry point for the integration of S via the node associated to T (node(T)). Thus, from one node node(T), the description S is integrated several times, one integration per one entry point (determined from the pertinent type T). For instance, from node nd1 (Figure 2), S is integrated twice: first integration of S with entry point e1 and second integration of S with entry point e2.
Thus, a description S will reach a node Nd with a specific entry point e (S/e) and it will be compared to the description N of Nd. Since N has no specific entry point associated to it, the comparison of S/e with N may still produce different results, since different concepts from N may be considered (in turn) as entry points that can match the concept e and initiate the comparison operation. This is exactly what is done by the comparison operation: it identifies concepts from N that can match the concept e, and for each identified concept c1 it performs a generalization operation on S/e and N/c1. The best generalization between S/e and N is then selected (the best generalization is the one that leads to the maximum number of matched relations between S/e and N).
In conclusion, a description S may reach a node Nd several times with different entry points. The integration process records these multiple visits of S to a node Nd. Each time S reaches Nd with a specific entry point e, the integration process checks if S/e has been already compared to the description of Nd. If yes, no comparison is done (because it will produce the same result) and the result of the previous comparison is considered. Otherwise, the comparison is done again between S/e and the description of Nd. why ? Because the same matching operation on the same CGs but with different entry points may produce different results (these different results can be interpreted as different perspectives).
A detailed description of the dynamic integration process is much more complex than this general description; several specific cases should be considered (depending on the type of the nodes to compare). This process has also some features that are not considered in this section (explicitation of the new description to integrate, contraction and compression of descriptions, identification of synonymy, etc.). Section More details and More Examples presents these points.
Dynamic integration process is sensitive to pertinent types
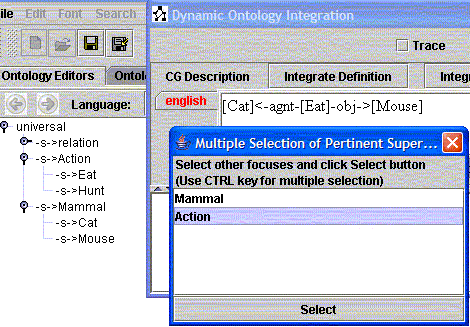
As expected, dynamic integration process is sensitive to pertinent types (the initial set of indexes): integration of a new description with different lists of pertinent types will produce different changes in the ontology/KB. Consider for instance the following example: integration of four situations with specific pertinent types (these situations are taken from an example proposed by J. Sowa about CG Generalization Hierarchy):
[Eat]-agnt->[Mammal] with pertinent types: Eat,
[Eat]-obj->[Mammal] with pertinent types: Eat,
[Cat]<-agnt-[Eat]-obj->[Mouse] with pertinent types: Eat,
[Cat]<-agnt-[Hunt]-obj->[Mouse] with pertinent types: Hunt
To run this example, load first the ontology "samples/ontology/CatMouse.xml". Situations used in this example are stored in the file dataForDynamicOntology/CatMouseExple.txt. The result of the integration is shown in Figure 4:
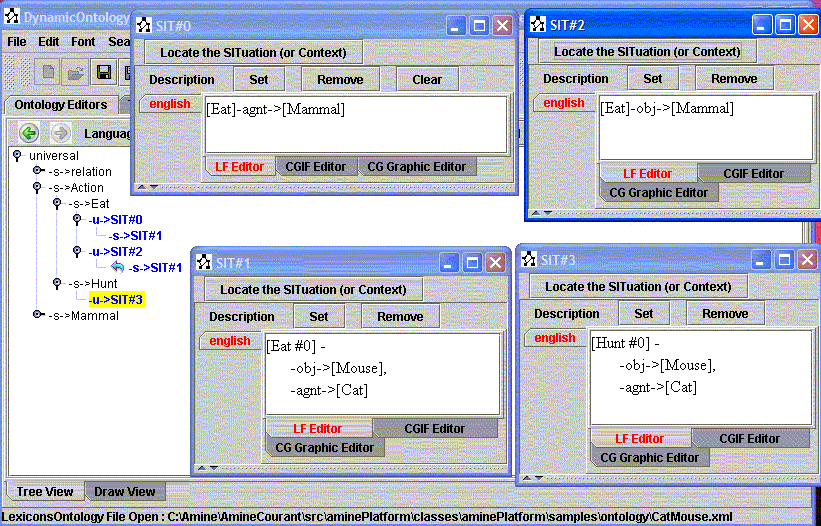
Figure 4: Integration with specific pertinent types
Let us consider now the integration of the same set of situations, but with different pertinent types:
[Eat]-agnt->[Mammal] with pertinent types: Eat and Mammal,
[Eat]-obj->[Mammal] with pertinent types: Eat and Mammal,
[Cat]<-agnt-[Eat]-obj->[Mouse] with pertinent types: Eat and Cat,
[Cat]<-agnt-[Hunt]-obj->[Mouse] with pertinent types: Hunt and Cat
The result of the integration is shown in Figure 5. As illustrated by this figure, a whole part (part enclosed by the colord circle) has been added as a consequence of the integration, of the same set of situations but via different list of pertinent types (than those used in Figure 4).

Figure 5: Integration of the same situations with different pertinent types
Figure 6 shows another integration of the same set of situations, with the same order, but with other pertinent types:
[Eat]-agnt->[Mammal] with pertinent types: Mammal and Action,
[Eat]-obj->[Mammal] with pertinent types: Mammal and Action,
[Cat]<-agnt-[Eat]-obj->[Mouse] with pertinent types: Eat, Action and Mammal,
[Cat]<-agnt-[Hunt]-obj->[Mouse] with pertinent types: Hunt, Action and Mammal,
Again the result of the integration is different from the previous integrations (Figure 6).


(a) The tree view (b) The Drawing view
Figure 6: Integration of the same situations with different pertinent types
This simple example illustrates the fact that the integration process is sensitive to pertinent types.
SuperTypes of (initial) pertinent types are proposed (also) for pertinent types
Previous section shows how dynamic integration process is sensitive to pertinent types. To provide a large set of pertinent types, the integration process provides not only the types specified in the description, but also their superTypes. Figure 7.a shows the first set of pertinent types (those specified in the description) and Figure 7.b the second set (superTypes of types in the first set). For the integration of each new description, Dynamic Ontology/KB GUI provides the two sets of pertinent types and waits for the (multiple) selection of the user.
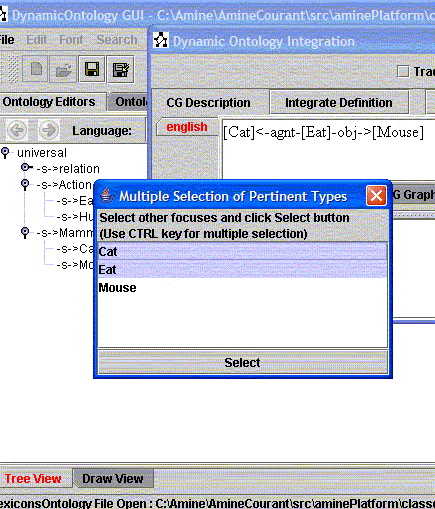
(a) Pertinent Types specified in the description (b) Pertinent Types that are superTypes of (a)
Figure 7: Pertinent Types
We used this possibility in the previous section: situations [Cat]<-agnt-[Eat]-obj->[Mouse] and [Cat]<-agnt-[Hunt]-obj->[Mouse] were integrated via the pertinent super-type Action (Action is a super-type of both Eat and Hunt).
More complex treatment when integration/propagation is done via individuals
Individuals of a type N are indexed under N (Figure 8.a). When a new description S is propagated to all the children of N, the propagation includes also all individuals that are indexed under N (Figure 8.a). The important point here is that S is not compared to the node if this node is an individual (like I1, I2 and I3), it is propagated (to be compared) to the children of the individual node (in our example: S is propagated to S2 and S3, children of I1, and it is propagated to S4 and S5, children of I3) (Figure 8.b). Recall however that a situation S may be propagated to children of an Individual (i.e. children S2 and S3 of I1 in Figure 8.b) not because the later is contained in S, but because we want to compare S with situations that are indexed under Individual nodes.
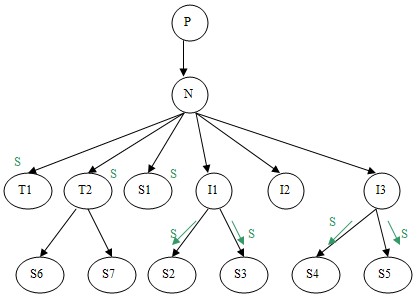
(a) (b)
Figure 8: Integration via Individuals
If the current entry point e associated to S (S/e) has a designator that corresponds to the current child (i.e. the child is an Individual I), then the new description S/e is considered as more specific than the Individual node I and it is propagated to the children of I and it will be placed/indexed under node I (directly as a child or indirectly as a descendant). Otherwise (the entry point has not a designator that corresponds to the current child), the new description S/e will be compared to the children of I but it will not be considered as more specific than the Individual node I, S/e is considered as more specific than the father (the type) of the Individual node I.
The following example illustrates these points and also the integration via individuals. To run the example, load first the ontology "samples/ontology/CyrusSample.xml". Situations used in this example are stored in the file dataForDynamicOntology/CyrusSample.txt. This example is a reformulation of events used by the program CYRUS developed by Kolodner [Kolodner] to illustrate basic principles of dynamic memory (of events). The example has been "converted" as an example for dynamic ontology by Karim Bouzouba. Figure 9 provides the initial content of the ontology "CyrusSample".

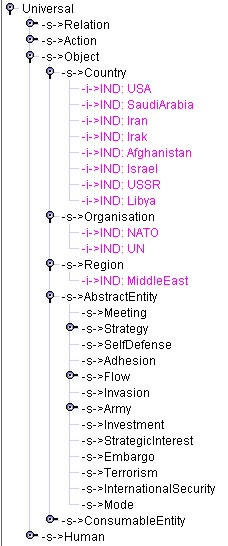
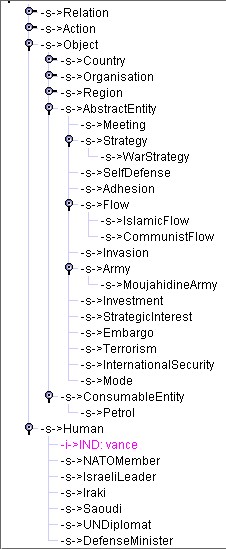
(a) (b) (c)
Figure 9: The initial content of "CyrusSample" ontology
Assume that we have to integrate the following situation with pertinent type Country:
[Treat]-
-agnt->[Human:vance],
-with->[Country:Irak],
-obj->[WarStrategy]
Figure 10.a presents the result of the integration of this situation: pertinent type Country points to the entry point [Country:Irak]. Hence, the new situation SIT#0 is integrated with this entry point: SIT#0/[Country:Irak]. When SIT#0 arrives to the Individual node Irak, the latter has no child and the new situation is considered as a (new) child of Individual node Irak, not as new child of Type node Country, because the designator in the entry point is the same as the current Individual node (Irak). Thus, the new situation is indexed under Individual node Irak (since the only pertinent type specified was Country: the new situation is about Irak). Nothing is done when SIT#0 arrives to the other Individual nodes under Country.

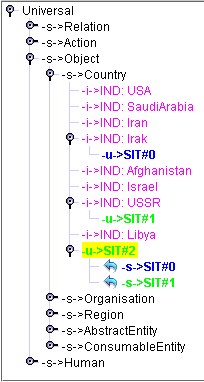

(a) (b) (c)
Figure 10: Integration via Individuals I
Let us consider now the integration of the following new situation with pertinent type Country: pertinent type Country points to the entry point [Country:USSR]. Hence, the new situation SIT#1 is integrated with this entry point: SIT#1/[Country:USSR].
[Negotiate]-
-agnt->[Human],
-with->[Country :USSR],
-obj->[WarStrategy]
The result of the integration of this situation is shown in Figure 11.b. The new situation SIT#1 is indexed under Individual node USSR (like the case of the previous situation). But the important point is that SIT#1, is propagated not only to the Individual node USSR but also to the other Individual nodes of Country, including the Individual node Irak. Then, SIT#1 is compared to the child of the node Irak: SIT#0. The two situations have a common information (S2 = SIT#2, Figure 11.c). Please, note that the father of S2 is not the node Irak but the node Country (Figure 11.c), because Irak is not contained in S2 (i.e. S2 is not a specialization of Irak).
A similar result will be obtained if instead of the above situation (on USSR), we integrate the following situation (represented in Figure 11.a by S2) with pertinent type Country: pertinent type Country points to the entry point [Country]. Hence, the new situation SIT#2 is integrated with this entry point: SIT#2/[Country].
[Negotiate]-
-agnt->[Human],
-with->[Country],
-obj->[WarStrategy]
As illustrated by Figure 11.a, the common situation (S1) is indexed under the Type node Country (not Irak) since Irak is not contained in the description of S1. Treatment is done as if S2 was propagated directly from Type node Country to the node S0. Since S0 and S2 have a common information, stored in S1, the latter is placed as specified in Figure 11.a with the real father Country.

(a) (b)
Figure 11: Integration via Individuals II
However, a different result will be obtained if instead of the two above situations (the first on USSR and the second on an unkonwn Country), we integrate the following situation (represented in Figure 11.b by S2) with pertinent type Country: pertinent type Country points to the entry point [Country:Irak]. Hence, the new situation S2 (SIT#2) is integrated with this entry point: S2/[Country:Irak].
[Negotiate]-
-agnt->[Human],
-with->[Country],
-obj->[WarStrategy]
As illustrated by Figure 11.b, the common situation (S0) is indexed under the Individual node Irak since Irak is contained in the description of S0: S2 has been propagated from the Individual node Irak to its child S1 because S2 is really a specialization of Irak and S0 is indexed under the Individual node Irak because it is a real father for S0.
We will consider now a more complex example. Figure 12 presents four events to integrate in Cyrus Ontology (according to its initial content, Figure 9).

Figure 12: Four events to integrate in the current Ontology
Figures 13 and 14 show the result of the integration of the first and second events (Evt1 and Evt2). Integration of Evt1 is done with pertinent types: Human and Organisation. Integration of Evt2 is done with pertinent types: Human, Country and Organisation.
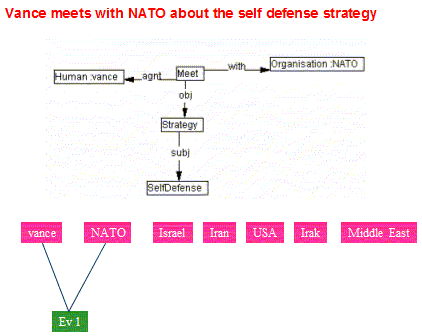
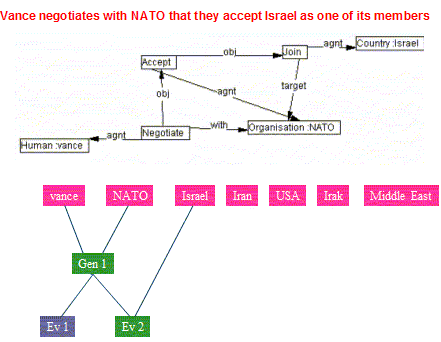
Figure 13: Result of the integration of the first and second events
Figure 14 shows the same result as displayed by the "Tree View" of the ontology.

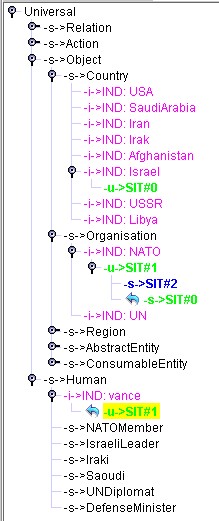
(a) Result of dynamic integration of Evt1 (SIT#0) (b) Result of dynamic integration of Evt2

(c) Content of SIT#0, SIT#1 and SIT#2. SIT#1 is a common generalization of SIT#2 & SIT#0
Figure 14: Result of the integration of the first and second events in the Ontology
Note on Figures 13 & 14: Ev1, Ev2 and Gen1, in Figure 13, correspond to SIT#2, SIT#0 and SIT#1 respectively. Note also that situations are renamed (with different ranges) at each new integration.
Figure 15 shows the result of the integration of the third event (Evt3 is represented by SIT#0 = S1). Integration of Evt3 is done with pertinent types: Human, Country, Region and Organisation.
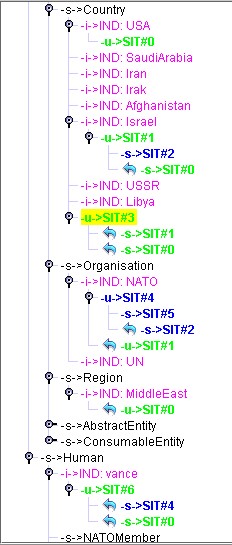
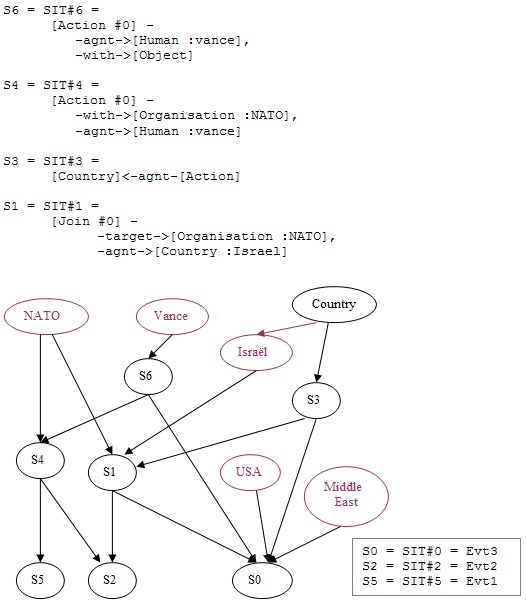
Figure 15: Result of the integration of the third event
Reader can continue with the integration of Evt4 and the other events described in file dataForDynamicOntology/CyrusSample.txt.
Trace facility
Dynamic integration process provides a trace facility; user can switch on/off the parameter "trace" (with getTrace() and setTrace() methods). Trace provides the detail of the integration, step by step. The listing of the trace is reported in the output stream (with System.out.println()) and it is stored in a log file called "dynamicOntologyLog.txt", with the full path aminePlatform/samples/ontology/dynamicOntologyLog.txt. This file can be edited with any text editor to debug or to perform an in-depth analysis of the integration process.
Dynamic Knowledge Integration Process can be performed according to, at least, two modes: Generalization-Based Integration and Classification-Based Integration. Definition of these two modes depend on the use of the comparison operation and on the kind of information to integrate. We discuss the two modes of dynamic knowledge integration process according to these parameters.
The two modes of dynamic knowledge integration process and the comparison operation
In the case of Generalization-Based Integration, all the five result of the comparison operation are considered. In the case of Classification-Based Integration, the case "the new description and the current description have only some common information" is not considered; no general common node is created. The case of Information Retrieval is similar to the Classification-Based Integration except that no addition or change are made during the classification-based integration process. The goal is to locate the "position" of the new description in the ontology/KB/memory; to check if there is a node with a content that is equal to the specified description and to locate the nearst generalizations (fathers) and the nearst specializations (children) of the specified description.
More details on the three integration modes are provided in the following sections.
Different kinds of Information and of Ontology/KB/Memory and of Dynamic Integration Process
There are different kinds of ontology/KB/memory, and so different versions of Dynamic Integration Process should be developed for each kind. Among these kinds of Ontology/KB/Memory: Type definition (terminological) ontology/KB, situation-based KB/memory, rule-based ontology/KB/memory, situation & rule based KB/memory, Heterogenous/Integrated ontology/KB/memory. Following sections present the different versions of Dynamic Integration Process, developed for the specified kinds of ontology/KB/memory.
Definition Integration Process
See Definition Integration Process.
Situations Integration Process
See Situations Integration Process.
See Rules Integration Process.
Situations and Rules Integration Process
It is possible to integrate both situations and rules in the same application. The following example illustrates this possibility. Please note that comparison between Situation and Rule is discussed in Rules Integration Process.
Figure 16 shows the initial state of the ontology ("CatMouse.xml") with the setting for the classification of a CSRule (i.e. selection of integration mode "Classification" and selection of CS type "CSRule").

Figure 16: The initial state of the ontology/KB/memory
Figure 17 shows the frame "Classification Based Integration of Rule" that is provided for the edition and the initiation of the classification process.
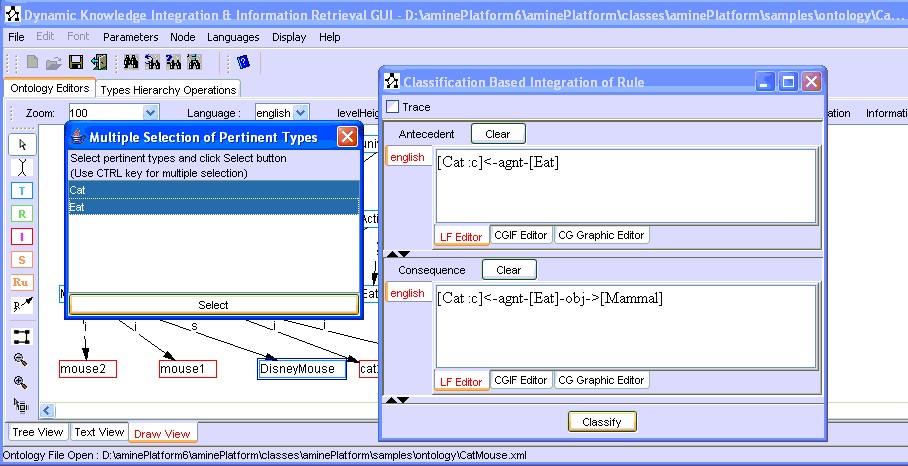
Figure 17: Classification of a CSRule
Figure 18 shows the result of the classification.

Figure 18: Visualization of the result of the Classification of the CSRule
Figure 19 shows the selection of "Classification" followed by the selection of "Situation" for the classification of a new situation.

Figure 19: Selection of "Classification" followed by "Situation"
As shown in Figure 20, the frame "Classification Based Integration of Situation" is displayed in order to edit a situation and initiate its classification.

Figure 20: Classification of a Situation
Figure 21 shows the result of the situation classification; the situation is more general than the antecedent of the rule integrated previously.
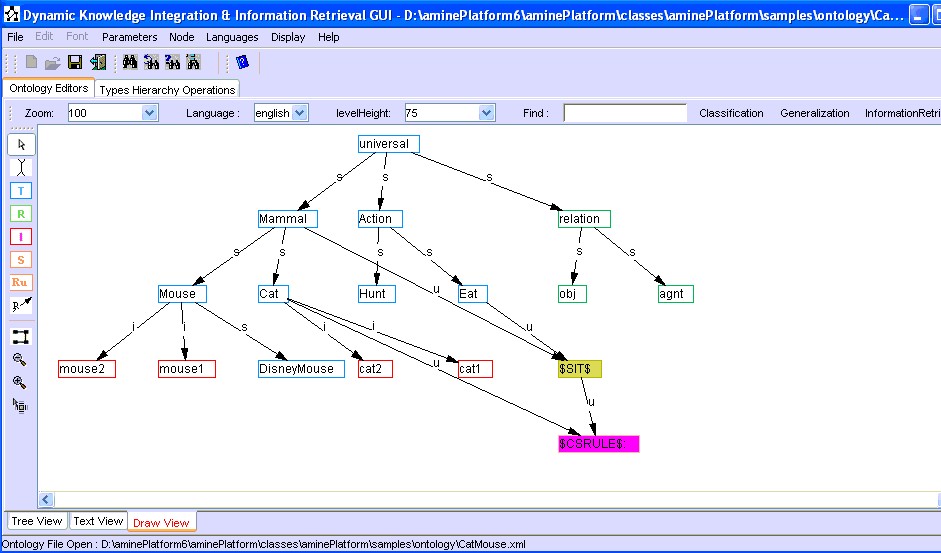
Figure 21: The result of Situation Classification
Figures 22-23 show the edition and classification of another rule.

Figure 22: Classification of a new Rule
Figure 23 shows the result of the classification of the second rule.

Figure 23: Result of the Classification of the new Rule
The example illustrates how situations and rules can be integrated/classified in the same application.
Heterogenous Integration Process
See Heterogenous Integration Process.
Knowledge integration process and other components of Amine (like Prolog+CG)
The following example illustrates how dynamic integration process can be called easily from a Prolog+CG program.
integrateSituation(G, L) :- //call the method integrateSituation() to integrate a situation with pertinent types
getOntology(_ontology), // getOntology() is a primitive goal in Prolog+CG
"aminePlatform.engines.dynamicOntology.DynamicOntology":integrateSituation(_ontology, G, L), !.
...
?- integrateSituation([Robot]<-agnt-[Wash]-thme->[Car],
[Robot, Wash, Car]).
yes
Contextual Description Integration Process
Dynamic Integration of Contextual Descriptions, expressed by compound CGs for instance, can be performed according to two modes: "soft/superficial" dynamic integration of contextual description, or "indepth" dynamic integration of contextual description.
Soft/superficial dynamic integration process of contextual descriptions requires no special treatment; a contextual description is integrated in the same way as a simple (no contextual) description. Figures 24-25 provide a simple example of Generalization-Based Integration Process. Figure 24 shows two situations to integrate, both are represented by contextual descriptions, i.e. compound CG.
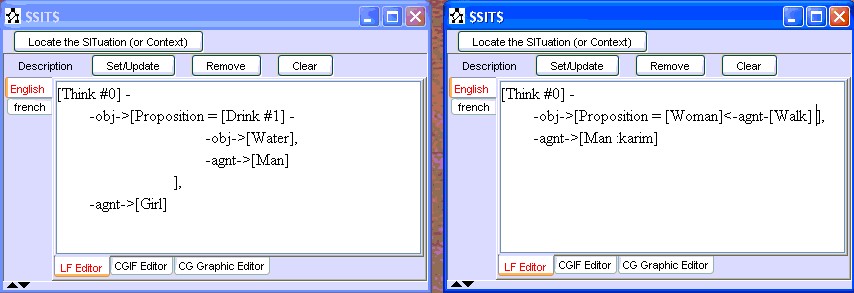
Figure 24: Two Contextual Descriptions (situations)
The result of Generalization-Based Integration of the two situations is provided in Figure 25: comparison of the two compound CG corresponds to a recursive comparison operation that considers the embedded contexts.
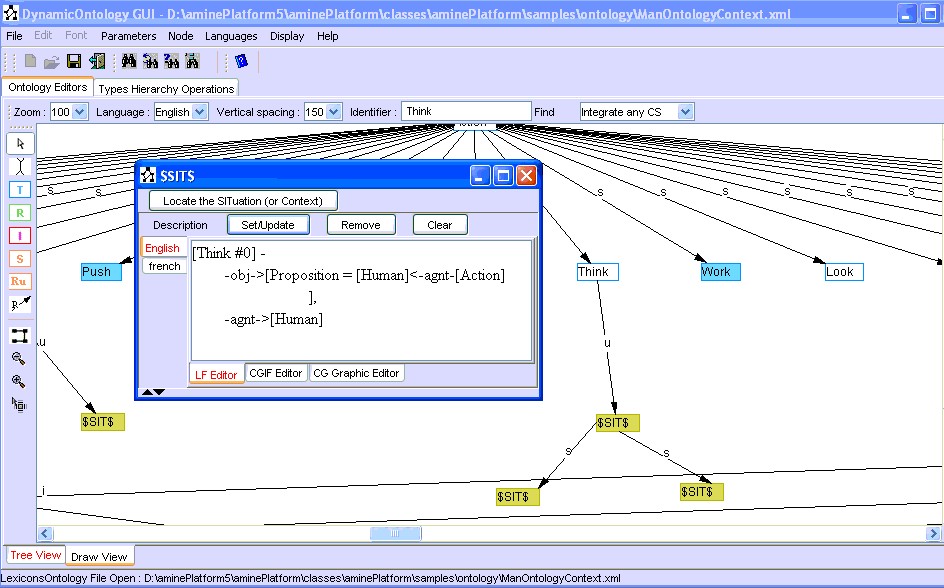
Figure 25: Result of Generalization-Based Integration of two Contextual Descriptions (situations)
In soft/superficial dynamic integration process of contextual descriptions, contexts are considered as local to the descriptions; information specified in an embedded context is not compared and related to other information in the ontology/KB/memory. However, indepth Contextual Description Integration Process considers contexts as embedded contexts/compounds of composed Descriptions/CGs and also as sources of information in themselves.
Indepth Contextual Description Integration Process is described in Indepth Contextual Description Integration.
Old version of Dynamic Ontology
See the old version of Dynamic Ontology.
See Dynamic Ontology GUI for the activation and use of Dynamic Integration Process, via Dynamic Ontology/KB/Memory GUI.
Due to dynamic integration of a continues stream of (contextual) information, Ontology/Memory becomes quickly very dense and the integration process becomes quickly a consuming process because the new description is propagated via several paths, involving several calls of comparison operation. For contextual information, integration is a "multi-layer integration process" (i.e. recursive integration of the embedded contexts) which is a more consuming process than a non-contextual integration process. The magnitude of the "complexity" of the integration process (according to the cost of the process in time and space) depends on several parameters, among them:
complexity of the new information to integrate and of the existent information (that will be compared with the new information): some parameters that determine the complexity of the information treated by dynamic integration process are: is the information contextual or not ?, does the information contains embedded contexts or not ?, number of contexts, number of concepts and relations, etc.
cardinality of the set of pertinent types: the number of pertinent types to consider has an impact on the complexity of dynamic integration process (in terms of space and time): a small set of pertinent types may lead to a "more localized and reduced" integration process.
density and connectivity of existent information in the ontology: an existent description, to compare with the new description, that have a small number of children may lead to a more localized and reduced integration process.
features of knowledge representation formalism and characteristics of the comparison operation: when descriptions are represented by general CG, a comparison of two descriptions may produce (several) different results, each result may/should be integrated in its own, and so on. This "explosive" integration process can be reduced by using "restricted" CG (like functional CG). It can be reduced further if the comparison of the two descriptions produces at most one result (by reducing the representation formalism to headed functional CG).
evaluation of the comparison operation: the number of (ontology/memory) nodes will grow more quickly if a new node is created automatically (without any evaluation) when the new description has (only) common information with an existent description. More nodes may involve more comparisons (depending on the paths that the new information will follow during its integration/propagation in the ontology/memory). If an evaluation of the generalization is done and only "pertinent" generalization are considered, number of new created nodes will be reduced.
the "magnitude" of similarity required: the complexity of the integration process depends on the "magnitude" of the required similarity. For instance, in our current definition of the integration process, when the new description S is more specific that an existent description D, S is propagated to all children of D (in order to identify any similarity between S and any child of D). The magnitude of similarity can be reduced if only a subset of children of D is considered. Also, in our current definition of the integration process, when the new description S is integrated with an entry point that contains a specific designator (as illustrated by the CYRUS example), it is propagated to all children of the type of the entry point (in order to identify any similarity between S and these children. When a child is a designator, S is propagated to the children of this child). The magnitude of similarity can be reduced if S is integrated only via the Individual node that represents the specific designator.
These parameters (and others) define in fact a family of dynamic integration processes: various variants of dynamic integration process can be defined and implemented, depending on the specific "tuning" of the above parameters. However, it is clear that a "natural" (and efficient) implementation of dynamic integration process requires a massively parallel system: ontology/memory is in general a huge graph of highly interconnected Conceptual Structure nodes, and dynamic integration process is a parallel activation and propagation based process; the new description is propagated, via different nodes, to several nodes. Propagation of the new description to a node activates (in general) the comparison operation, and depending on the result of the comparison, propagation may continue or not.
More experiments and an extensive analysis are needed to assess dynamic integration process.
Dynamic integration process is implemented as a package (Figure 35): dynamicOntology, with the full path aminePlatform.engines.dynamicOntology. Dynamic ontology GUI is implemented by the package: dynamicOntologyGUI, with the full path aminePlatform.guis.dynamicOntologyGUI.

Figure 35: dynamicOntology Package
The class that implements the integrated heterogenous integration process is DynamicOntology with the full path aminePlatform.engines.dynamicOntology.DynamicOntology. See heterogenous integration process for more detail on this class. Reader can consult Complementary Comments for more detail and, of course, he/she can consult the source code for a complete description. The classes IntegrateDefinition, IntegrateSituation and IntegrateCSRule are specialization of the class IntegrateCS which is an abstract class that implements the integration process for both definition, situation and rule. The same process is applied for the three subclasses (IntegrateDefinition, IntegrateSituation and IntegrateCSRule). The abstract class IntegrateCS provides the following methods that are inherited by its subclasses:
Constructors
public IntegrateCS(Ontology ont)
public IntegrateCS(Ontology ont, Lexicon lex)
public IntegrateCS(Ontology ont, Lexicon lex, JTextArea txtArea)
Member Methods for the three kinds/modes of the integration process
public IntegrationResult classify(Object csDescr, AmineList pertinentTypes)
public IntegrationResult classify(Object csDescr, AmineList pertinentTypes, AmineList superTypesPertinentTypes)
public IntegrationResult generalize(Object csDescr, AmineList pertinentTypes)
public IntegrationResult generalize(Object csDescr, AmineList pertinentTypes, AmineList superTypesPertinentTypes)
public IntegrationResult ask(Object csDescr, AmineList pertinentTypes)
public IntegrationResult ask(Object csDescr, AmineList pertinentTypes, AmineList superTypesPertinentTypes)
Static Methods for the three kinds/modes of the integration process
public static IntegrationResult classify(Ontology ontology, Object csDescr, AmineList pertinentTypes)
public static IntegrationResult classify(Ontology ontology, Object csDescr)
public static IntegrationResult generalize(Ontology ontology, Object csDescr, AmineList pertinentTypes)
public static IntegrationResult generalize(Ontology ontology, Object csDescr)
public static IntegrationResult ask(Ontology ontology, Object csDescr, AmineList pertinentTypes)
public static IntegrationResult ask(Ontology ontology, Object csDescr)
The differences between the three subclasses (IntegrateDefinition, IntegrateSituation and IntegrateCSRule) are "encapsulated" in the following abstract methods that are defined/implemented in IntegrateDefinition, IntegrateSituation and IntegrateCSRule:
protected abstract boolean isEmpty(Object newDescr);
protected abstract CS newCS(Object newDescr);
protected abstract Enumeration findConceptsWithType(Object newDescr, CS pertinentType);
protected abstract Enumeration getConcepts(Object newDescr);
protected abstract boolean sameTypeOfCS(CS newOntNode, CS currentOntNode);
protected abstract boolean identicalTypeOfCS(CS newOntNode, CS currentOntNode);
protected abstract void setContentOf(CS newOntNode, CS currentOntNode);
protected static AmineList getConceptTypes(Object situationDescr) {
return null;
}
protected static IntegrateCS createIntegrateCS(Ontology ontology, Lexicon lexicon) {
return null;
}
Implementation of The Core of the Integration Process
The Integration Process is basically a propagation process of the new description "through" the ontology. The propagation of the new description in the ontology/memory is implemented by the three methods:
Propagation of the New Node (created for the new description) via all the pertinent types (focues) specified in focusHshMap and their associated entry points. The method is:
void
propagateNewNodeViaFocus(HashMap focusHshMap, CSWrapper newOntNodeWrapper,
boolean simulation, HashMap compareNodesHshMap,
ArrayList contextsToIntegrate, CG mainContext);
Compare and proceed, according to the result of the comparison. The method is:
boolean
compareAndProceed(CSWrapper newOntNodeWrapper, Concept entryPoint, CS
fatherOntNode,
CS currentOntNode, boolean realComparison, boolean simulation,
HashMap compareNodesHshMap, ArrayList contextsToIntegrate,
CG mainContext);
This method considers first the case where the two nodes have been already compared and update the memory accordingly. This case can happen because a new information can be propagated from different nodes. Then we consider the case where the two nodes have not yet been compared. The general treatment is to call compare operation and then call proceed method which resumes the integration process according to the result of the comparison.
Proceed according to the result of the comparison. This method considers the five cases (more general, more specific, equal, have common information, incomparable). The method is:
void proceed(CSWrapper
newOntNodeWrapper,Concept entryPoint, CS currentOntNode, CS fatherOntNode,
boolean realComparison, CompareCGResults compareCGResults, boolean simulation,
HashMap compareNodesHshMap, ArrayList contextsToIntegrate, CG mainContext);
See body of these methods for a complete description.
References
- Kabbaj A., Self-Organizing Knowledge Bases: The Integration Based Approach, in Proc. Of the Intern. KRUSE Symposium : Knowledge Retrieval, Use, and Storage for Efficiency, Santa Cruz, CA, USA, 1995.
- Kabbaj A., Un système multi-paradigme pour la manipulation des connaissances utilisant la théorie des graphes conceptuels, Ph.D Thesis, DIRO, U. de Montréal, Juin, 1996.
- Kabbaj A., H. Erramli and K. Mousaid, An integration-based approach to dynamic formation of a knowledge-base: The method and its applications, submitted to the 7th Int. Conf. on Conceptual Structures (ICCS'99), 1999.
- Kabbaj A., H. Erramli and K. Mousaid, La formation dynamique d’une base de connaissance dans SYNERGY, 2000.
- Kolodner J. L., Maintaining Organization in a Dynamic Long-Term Memory, Cognitive Science 7, 243-
280, 1983.
- Kolodner J. L., Case-Based Reasoning, Morgan Kaufmann, 1993.
- Lebowitz M., Concept learning in a rich input domain: Generalization-based memory, in Machine Learning, Vol. 2, Michalski R. M., and al. (eds.), Morgan Kaufmann, 1986.
- Pazzani M. J., Creating a memory of causal relationships: An Integration of Empirical and Explanation-Based Learning Methods, Lawrence Erlbaum Associates, 1990.
- Salveter S. C., Inferring Conceptual Graphs, Cognitive Science 3, pp. 141-166, 1979.
- Schank R. C., Dynamic Memory: A Theory of Learning in Computers and People, Cambridge University
Press, 1982
- Schank R. C., Tell Me a Story: A new look at real and artificial memory, MacMillan, 1991.
- John F. Sowa, Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks Cole Publishing, 2000.